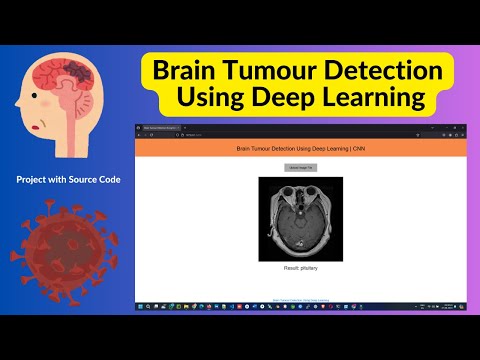
Image colorization is an intriguing task in the field of computer vision that involves adding color to black and white images. This process transforms historical photographs, enhances low-quality video footage, and brings new life to vintage images. The advent of deep learning, particularly Convolutional Neural Networks (CNNs), has significantly improved the accuracy and realism of automated colorization.
In traditional image processing, colorization required manual effort and expertise, making it a time-consuming and labor-intensive task. However, with the development of AI and deep learning, we now have models that can learn from large datasets of color images and predict the appropriate colors for grayscale images. This not only saves time but also produces remarkably realistic results.
OpenCV (Open Source Computer Vision Library) is a powerful tool for computer vision and image processing. It provides a wide range of functions for manipulating images, making it an excellent choice for implementing AI-based image colorization. By leveraging OpenCV along with deep learning models, we can automate the process of colorizing black and white images with impressive accuracy.
This report delves into the methodology and implementation of AI-based black and white image colorization using OpenCV. We will discuss the conversion of images to different color spaces, the training of neural networks to predict color channels, and the application of these models to achieve vibrant and realistic colorization of grayscale images.
Technology Overview
Image colorization using AI and OpenCV is a fascinating blend of deep learning and computer vision technologies. Here's an overview of the key technologies and concepts involved:
- Deep Learning and Convolutional Neural Networks (CNNs):
- Deep learning is a subset of machine learning that uses neural networks with many layers to model complex patterns in data.
- CNNs are a type of deep learning model particularly effective for image processing tasks. They consist of layers that automatically and adaptively learn spatial hierarchies of features from input images.
- Color Space Conversion:
- Images are typically processed in RGB color space but for colorization, conversion to Lab color space is common.
- In Lab color space, the L channel represents lightness, while the a and b channels represent color information (chromaticity). This separation makes it easier for the model to predict color components.
- Training the CNN Model:
- The model is trained on a large dataset of color images, learning to predict the a and b channels given the L channel.
- Training involves feeding the network pairs of grayscale (L channel) and color (a and b channels) images, and optimizing the network to minimize the difference between predicted and actual color channels.
- Implementation with OpenCV:
- OpenCV is a widely-used library in computer vision for image manipulation and processing. It provides tools for tasks like loading images, converting color spaces, and applying transformations.
- OpenCV's
dnnmodule can be used to load and run pre-trained CNN models, making it possible to integrate deep learning models into applications for tasks like colorization.
- Application Process:
- Load the grayscale image.
- Convert the image to Lab color space.
- Use the trained CNN model to predict the a and b channels.
- Combine the predicted a and b channels with the original L channel.
- Convert the image back to RGB color space to get the final colorized image.
Benefits and Challenges
Benefits:
- Automates the colorization process, saving time and effort.
- Produces realistic and high-quality colorized images.
- Can be applied to various fields like film restoration, historical photo enhancement, and more.
Challenges:
- Requires a large and diverse dataset for training to achieve good results.
- May struggle with complex images where the grayscale cues alone are insufficient to infer accurate colors.
- Computationally intensive, requiring powerful hardware for both training and inference.
This combination of deep learning and computer vision techniques has opened up new possibilities in image colorization, making it more accessible and effective. Would you like to explore any of these technologies in more detail?